热点资讯
- Intel FPGA|如何挑选TERASIC友晶DE系列FPGA板卡?
- 资源|英特尔® Quartus® Prime设计软件的“后浪”来啦!
- Intel FPGA|如何挑选TERASIC友晶MAX 10系列FPGA板卡?
- 教育部中南地区电子电气基础课教学研究会
- 普源精电2024夏季新品发布会
- Intel FPGA|如何挑选TERASIC友晶Stratix 10系列FPGA板卡?
- 贺中国地质大学电子类测试分析仪器项目中标
- 2018 年友晶科技产学合作协同育人项目
- Intel FPGA|如何挑选TERASIC友晶Cyclone V系列FPGA板卡?
- 集美大学《高级FPGA综合实验系统》完成交付验收

咨询热线:
18062095810
邮件: wangting@whhexin.com
电话:027-87538900
地址: 湖北·武汉·鲁巷·华乐商务中心1006
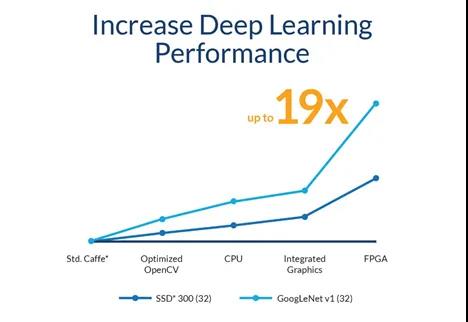
FPGA加速深度学习-Terasic友晶DE10-Pro
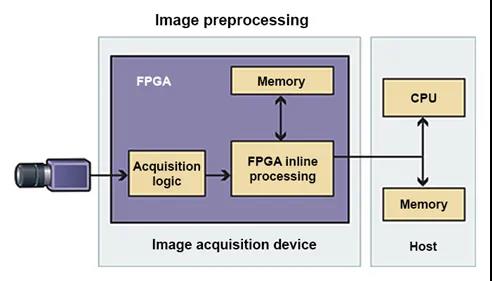
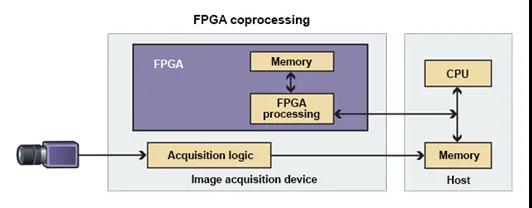
对于许多行业来说,深度学习是一种颠覆性的技术,但是其计算需求却远超标准的CPU,这就使开发人员不得不考虑其他架构。然而,从轻车熟路的CPU转向到更高深莫测的设计,无疑是个不小的挑战。其实,企业未必一定要改造现有的基础设施来支持深度学习,采用CPU + FPGA的混合计算架构也不失为一种可行之策。
为什么要采用CPU + FPGA的混合计算架构,而不完全舍弃CPU呢?从性能上来讲,单个推理是顺序操作,因而大部分处理器可以有效地执行独立的深度学习推理工作。只是当推理操作以批量或大容量呈现时,CPU就很难跟上了。
此时,GPU和其他大规模并行架构就会提供串行处理的替代方案。大规模并行非常适合批量推理工作,以及训练具有大量输入数据集的深度学习模型。
当然,当涉及到顺序处理时,并行计算机通常是低效的。对于需要快速顺序推理的应用程序,例如自动驾驶汽车的计算机视觉和其他时间敏感的应用程序,GPU就提供不了最优方案了。
因而,为了满足低容量推理和大批量处理的需求,将FPGA与多核CPU进行集成的设备是一个很有吸引力的选择。FPGA在本质上是大规模并行的,所以它来执行大量的深度学习,轻而易举。另一方面,较小的顺序操作可以由CPU处理。或者,可以在FPGA和CPU之间共享工作负载,以优化神经网络的效率。
而且,基于这种异构体系结构的灵活性,开发人员可以在不必彻底检查现有计算基础结构的情况下实现这种优化。